Build a Resilient Disaster Recovery Strategy for Business Continuity

How Brainboard Helps
Chaos during downtime is not a technical failure; it is a lack of preparation. Brainboard's disaster recovery services change that: teams get a unified platform for collaborative planning, failure scenario simulation, and automated recovery - from the infrastructure level to the application level.No confusion when an incident occurs: roles are clear, processes are well-rehearsed, and recovery starts automatically. The result is predictable recovery and reliable business continuity, rather than frantic, panicked actions.
People
An effective disaster recovery strategy requires coordinated efforts from the infrastructure team, developers, and security and compliance specialists. Brainboard provides overall visibility for all participants: everyone knows their role, sees the status, and acts in line with a unified plan. No more "who is responsible for this component?" at the most inopportune moment.
Tooling
A cloud disaster recovery strategy starts with a clear definition of RPO and RTO - how much data can be lost and how quickly it must be recovered. Brainboard embeds these parameters directly into the architecture, allowing you to simulate failure scenarios and automate the entire recovery process. Visual tools allow you to test procedures in advance, rather than figuring them out under the pressure of an incident.
Process
A synchronized disaster recovery plan is one in which the DR environment is always identical to production and ready to deploy at the first signal. Brainboard provides this through a visual environment, CI/CD integration, and a versioned architecture catalog. A reproducible approach eliminates manual errors, maintains consistency across regions, and significantly speeds up recovery time in any scenario.
The Challenge
Business continuity and disaster recovery are currently manual processes for most companies, and no one tests them until it is too late. Protecting cloud workflows is complicated by vendor lock-in, a lack of standards, and fragmented processes across different teams.When a real failure occurs, it turns out that there is no DR strategy at all, or it exists only on paper. Teams are not coordinated, and no one knows exactly what to do and in what order.The outcome is predictable: prolonged downtime, data loss, financial damage, and a blow to reputation. The problem is not with the technology - it's that disaster recovery is perceived as a task for later, which never gets done.
Current State
- Uptime is assumed, but failure is inevitable
- No DR strategy or inconsistent processes
- Cloud vendor lock-in limits failover options
- Teams lack alignment during outages
Business Impact
- Data loss and downtime hurt revenue
- No way to test or simulate DR events
- Operations remain stalled during incidents
- Recovery time is long and unpredictable

Technical Deep Dive Behind IaC Migration
IT disaster recovery at Brainboard is built on several technical levels.
Core Concepts


Implementation Process
Monitoring & Governance
.webp)
Architecture Overview
Before Brainboard, engineers faced overwhelming complexity: they had to understand Terraform, cloud services, networking, and security simultaneously - without breaking production.Cloud infrastructure solutions Brainboard changes this picture: engineers start with what they already know, and the platform guides them through each step. The visual interface translates complex concepts into understandable blocks. Best practices are built into templates. The entire lifecycle - build, update, and manage - is managed in a single, user-friendly platform, without the need to switch between tools and documentation.

Your current infra
Existing multi-cloud resources (AWS, Azure, GCP) with region-based setups and limited DR automation.

Your current infra
Centralized platform for visual recovery planning, RTO/RPO definition, simulation workflows, and cross-team collaboration.
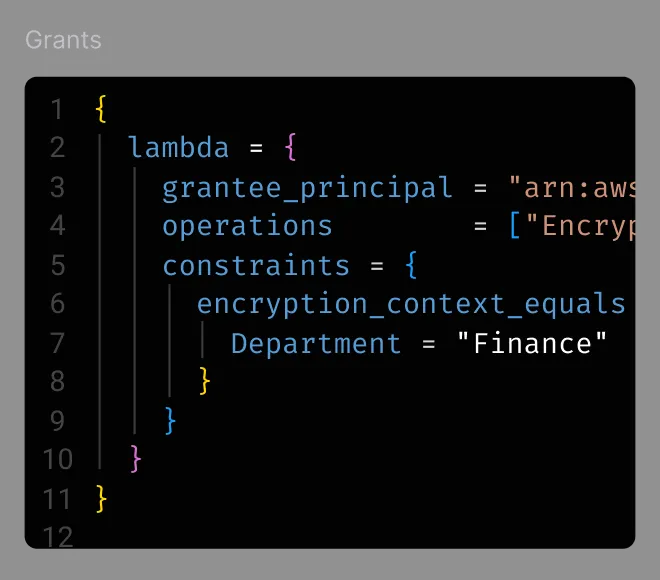
DR-ready infrastructure
Production-ready Disaster Recovery infrastructure as code, versioned, tested, and synchronized across environments
Benefits & Outcomes
The measurable results speak for themselves. Disaster recovery with Brainboard delivers three key outcomes:
Faster recovery after incidents - automated recovery flows start instantly, without waiting for the right engineer to get in touch.
Availability across regions - fully synchronized DR environments ensure failover without data loss and minimal downtime.
Audit-ready documentation - the entire history of changes, approvals, and actions during incidents is automatically recorded and available for compliance checks at any time.
Standardized DR environments
Maintain synchronized infrastructure blueprints that are always ready to deploy.
Cross-team alignment
Get security, infrastructure, and compliance teams on the same page with shared visual plans.
Improved customer trust
Show resilience with tested plans and clear recovery metrics — especially critical for regulated industries.
Fully automated failover
Trigger recovery flows programmatically or manually, reducing human error during incidents
Real-World Success
"Brainboard helped us build disaster recovery environments across three regions in days — not weeks. Now we simulate outages regularly, validate RPO/RTO, and recover confidently."



Enterprise SaaS Customer
50+ Engineers, Multi-cloud Infrastructure
Your questions, answered.
Didn’t find the answer to your question?
How does Brainboard handle RTO & RPO?
Can I simulate a disaster scenario?
Do I need to rebuild my infrastructure from scratch?
Can I manage multi-region DR setups?
What if my team isn't familiar with DR planning?
Didn’t find the answer to your question?