Azure extract and analyze call center data
This architecture deploys a complete Azure infrastructure for call center analytics using Azure OpenAI Service, Speech services, and Language services. The architecture processes recorded customer conversations to extract insights, sentiment analysis, and generate summaries.
Chafik Belhaoues
Updated
May 21, 2026
5
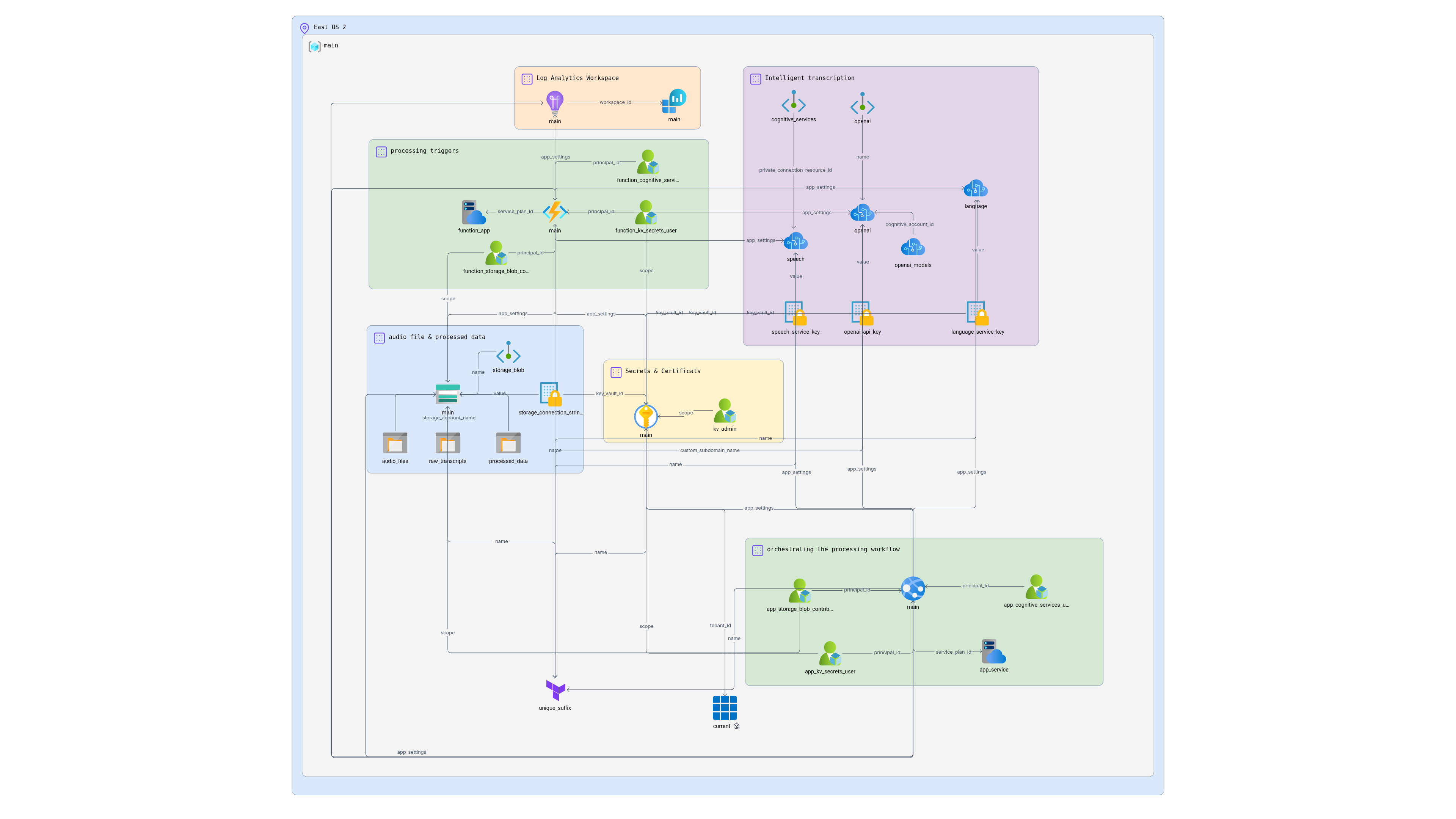
This architecture deploys a complete Azure infrastructure for call center analytics using Azure OpenAI Service, Speech services, and Language services. The architecture processes recorded customer conversations to extract insights, sentiment analysis, and generate summaries.
## Architecture Overview
The infrastructure includes:
- **Azure Blob Storage** - Store audio files and processed data
- **Azure Functions** - Process audio files with blob/timer triggers
- **Azure App Service** - Orchestrate the processing workflow
- **Azure OpenAI Service** - Perform analytics, summarization, and sentiment analysis
- **Azure AI Speech** - Convert speech to text transcription
- **Azure AI Language** - Detect and redact PII from transcripts
- **Azure Key Vault** - Securely store API keys and connection strings
- **Application Insights** - Monitor application performance
- **Role Assignments** - Proper permissions via managed identities
## Prerequisites
- Azure CLI configured and authenticated (`az login`)
- Terraform installed (version >= 1.2)
- Appropriate Azure permissions to create resources
- User object ID for Key Vault access (optional but recommended)
## Project Structure
```
├── provider.tf # Terraform provider configuration
├── locals.tf # Local values and naming conventions
├── variables.tf # Input variable definitions
├── terraform.tfvars # Variable values (customize for your environment)
├── main.tf # Core Azure resource definitions
└── README.md # This documentation
```
## Quick Start
1. **Clone or download the Terraform files**
2. **Customize the terraform.tfvars file**
```bash
# Get your user object ID for Key Vault access
az ad signed-in-user show --query objectId -o tsv
```
Update the `current_user_object_id` in `terraform.tfvars` with the returned value.
3. **Initialize Terraform**
```bash
terraform init
```
4. **Plan the deployment**
```bash
terraform plan -var-file="terraform.tfvars"
```
5. **Deploy the infrastructure**
```bash
terraform apply -var-file="terraform.tfvars"
```
6. **Verify deployment**
```bash
terraform show
```
## Configuration Options
### Naming Conventions
The Terraform configuration uses a smart naming strategy to handle Azure resource name constraints:
- **Standard Resources**: Use `{environment}-{project_name}` format (e.g., `dev-callcenter-rg`)
- **Name-Constrained Resources**: Use abbreviated format for resources with strict naming rules:
- **Key Vault**: `{env-3chars}{project-6chars}-kv-{random-6chars}` (e.g., `devcall-kv-a1b2c3`)
- **Storage Account**: `{env-3chars}{project-6chars}stg{random-6chars}` (e.g., `devcallstga1b2c3`)
This ensures compliance with Azure naming requirements (Key Vault: 3-24 chars, Storage: 3-24 chars lowercase alphanumeric).
### Environment Variables
| Variable | Description | Default | Required |
|----------|-------------|---------|----------|
| `environment` | Environment name (dev/staging/prod) | `dev` | No |
| `project_name` | Project identifier | `callcenter` | No |
| `location` | Azure region | `East US` | No |
| `current_user_object_id` | Your Azure AD object ID | `null` | Recommended |
### Azure Service Configuration
| Variable | Description | Default |
|----------|-------------|---------|
| `openai_sku_name` | OpenAI service tier | `S0` |
| `speech_service_sku` | Speech service tier | `S0` |
| `language_service_sku` | Language service tier | `S` |
| `app_service_plan_sku` | App Service plan size | `B1` |
| `function_service_plan_sku` | Function plan type | `Y1` (Consumption) |
### OpenAI Model Deployments
The configuration deploys two models by default:
- **gpt-35-turbo** - For conversation analysis and summarization
- **text-embedding-ada-002** - For semantic search and embeddings
You can customize models in the `openai_model_deployments` variable using the `sku_name` parameter.
### Security Features
- **Managed Identity** - All services use system-assigned managed identities
- **Key Vault Integration** - API keys stored securely and referenced via Key Vault
- **RBAC** - Least privilege access using Azure role assignments
- **Private Endpoints** - Optional network isolation (set `enable_private_endpoints = true`)
## Resource Connections
The infrastructure creates the following key relationships:
- **Function App** → **Storage Account**: Triggered by blob uploads or timer
- **Function App** → **App Service**: Calls processing endpoint
- **App Service** → **Speech Service**: Transcribes audio files
- **App Service** → **Language Service**: Detects/redacts PII
- **App Service** → **OpenAI Service**: Analyzes conversation content
- **All Services** → **Key Vault**: Retrieves API keys securely
- **All Services** → **Storage**: Reads/writes processed data
## Post-Deployment Steps
1. **Deploy Application Code**
- Upload your Function App code for audio processing triggers
- Deploy your App Service application for workflow orchestration
2. **Configure Processing Logic**
- Implement blob trigger functions for real-time processing
- Set up timer triggers for batch processing
- Configure OpenAI prompts for your specific analytics needs
3. **Set Up Monitoring**
- Configure Application Insights alerts
- Set up Log Analytics queries for operational insights
4. **Data Integration**
- Connect Power BI for analytics dashboards
- Integrate with CRM systems for processed insights
- Set up data retention policies
## Storage Containers
The storage account includes three containers:
- `audio-files` - Raw audio recordings
- `processed-data` - Final processed results
- `raw-transcripts` - Intermediate transcription files
## Security Considerations
- All API keys are stored in Key Vault, not as plain text
- Managed identities eliminate need for stored credentials
- Private endpoints available for network isolation
- HTTPS enforced on all endpoints
- Soft delete enabled on Key Vault and Storage
## Cost Optimization
- Function App uses Consumption plan (pay-per-execution)
- Storage uses Standard tier with appropriate retention
- Cognitive Services use Standard tiers (adjust for production)
- Consider reserved instances for production workloads
## Monitoring and Troubleshooting
- **Application Insights** provides performance monitoring
- **Azure Monitor** tracks resource health
- **Key Vault logs** show access patterns
- **Function App logs** help debug processing issues
## Cleanup
To destroy all resources:
```bash
terraform destroy -var-file="terraform.tfvars"
```
## Advanced Configuration
### Private Endpoints
For production environments, enable private endpoints:
1. Create a Virtual Network and subnet
2. Set up private DNS zones
3. Update terraform.tfvars:
```hcl
enable_private_endpoints = true
subnet_id = "your-subnet-id"
private_dns_zone_ids = {
"privatelink.blob.core.windows.net" = "your-dns-zone-id"
# ... other zones
}
```
### Remote State Storage
Configure remote state for team collaboration:
1. Create a storage account for Terraform state
2. Uncomment and update the backend configuration in `provider.tf`
3. Run `terraform init` to migrate state
## Support
For issues with:
- **Azure Resources**: Check Azure portal and activity logs
- **Terraform**: Review plan output and state file
- **Permissions**: Verify role assignments and Key Vault access
## Contributing
1. Follow Azure naming conventions
2. Tag all resources appropriately
3. Use managed identities for service authentication
4. Document any custom configurations
---
**Note**: This infrastructure creates the foundation for call center analytics. You'll need to develop and deploy the actual processing applications to the Function App and App Service created by this Terraform configuration.
Share:

